
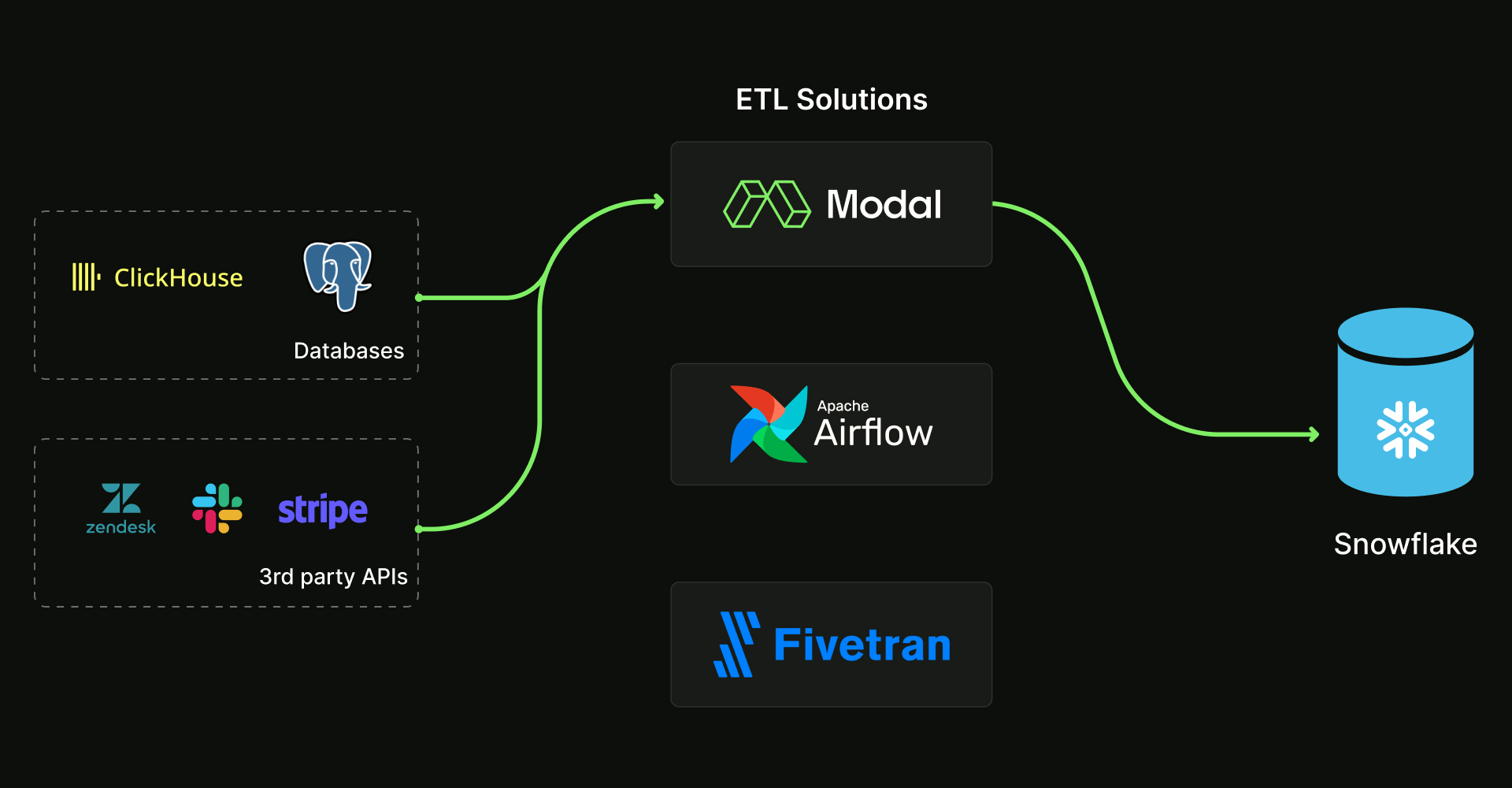
ETL (Extract, Transform, Load) is the process of moving data from point A to point B.
Most commonly, ETL means moving data from some source system (e.g. a production database, Slack API) into an analytical data warehouse (e.g. Snowflake) where the data is easier to combine and analyze. Most data teams use a vendor like Fivetran or an orchestration platform like Airflow to do this.
Modal is a great solution for ETL if you are primarily looking for:
- Cost savings on large-scale data transfers. Modal’s usage-based pricing means you pay for how much compute you use and not how many rows you sync, making it a far more cost-effective option for moving large amounts of data
- An easy and flexible platform for custom code. Orchestration platforms like Airflow are notoriously difficult to set up and are often overkill for 95% of data jobs that call for a simple cron-like scheduling pattern. Modal is the easiest way to get those kinds of custom ETL jobs running.
In this post, I’ll walk through two examples inspired by how we do our internal analytics that clearly show the cost and flexibility advantages of using Modal for ETL.
Example 1: Copy 12m ClickHouse rows to Snowflake at .01% of the cost of Fivetran
We use ClickHouse to serve metrics on resource usage and run time for our customers’ jobs. We’d like to move this data into Snowflake so that we can combine this data with other information we have on our customers and answer questions like “what is the conversion from a Modal workspace creation to using 1 hour of compute?”.
First, we extract from ClickHouse using their native Python connector:
def extract_from_clickhouse(date):
import clickhouse_connect
query = f"""
select
timestamp_minute,
workspace_id,
billing_type,
cpu_ns / 3600e9 as cpu_hr,
mem_ns / 3600e9 as mem_hr,
gpu_ns / 3600e9 as gpu_hr
from metrics
prewhere toDate(timestamp_minute) == '{date}'
"""
client = clickhouse_connect.get_client(
host=os.environ["CLICKHOUSE_HOST"]
port=os.environ["CLICHOUSE_PORT"]
username="default",
password=os.environ["CLICKHOUSE_PASSWORD"],
secure=True,
)
result = client.query(query)
print(f"Fetched clickhouse data for {date}")
return result.result_rowsThis returns the query results as a list of tuples, where each tuple is a row. Then we batch load the results into Snowflake:
def load_to_snowflake(data: list[tuple], date):
target_table = 'USAGE_BY_MINUTE'
batch_size = 10000
insert_sql = f"""
insert into CLICKHOUSE.{target_table} (timestamp_minute, workspace_id, billing_type, cpu_hr, mem_hr, gpu_hr, inserted_at)
values (%s, %s, %s, %s, %s, %s, current_timestamp())
"""
for i in range(0, len(data), batch_size):
batch = data[i : i + batch_size]
print(f"Loading batch {date}:{i}-{i+batch_size}")
cursor.executemany(insert_sql, batch)
conn.commit()
# Close the cursor and connection
cursor.close()
conn.close()
print(f"Data inserted successfully.")Here we are using Snowflake’s executemany function, which batch inserts 10,000 rows at a time. We set the batch size to 10,000 because Snowflake’s insert statement has a limit of 16,384 rows in a single call.
Now, we add some Modal 🪄magic🪄:
@stub.function(
secrets=[
modal.Secret.from_name("snowflake-secret"),
modal.Secret.from_name("clickhouse-prod")
],
timeout=3000
)
def run_etl(date):
results = extract_from_clickhouse(date)
load_to_snowflake(results, date)
@stub.local_entrypoint()
def main():
dates = [
'2024-04-07',
'2024-04-08',
'2024-04-09',
'2024-04-10',
'2024-04-11'
]
run_etl.for_each(dates)We use @stub.function to execute run_etl in the cloud with the following
parameters:
- Database credentials as environment variables via Secrets
- A timeout of 50 minutes (default is 5 minutes)
In main(), we kick off 5 run_etl jobs in parallel by date using
for_each to greatly
speed up processing time.
Here are the statistics of an example run:
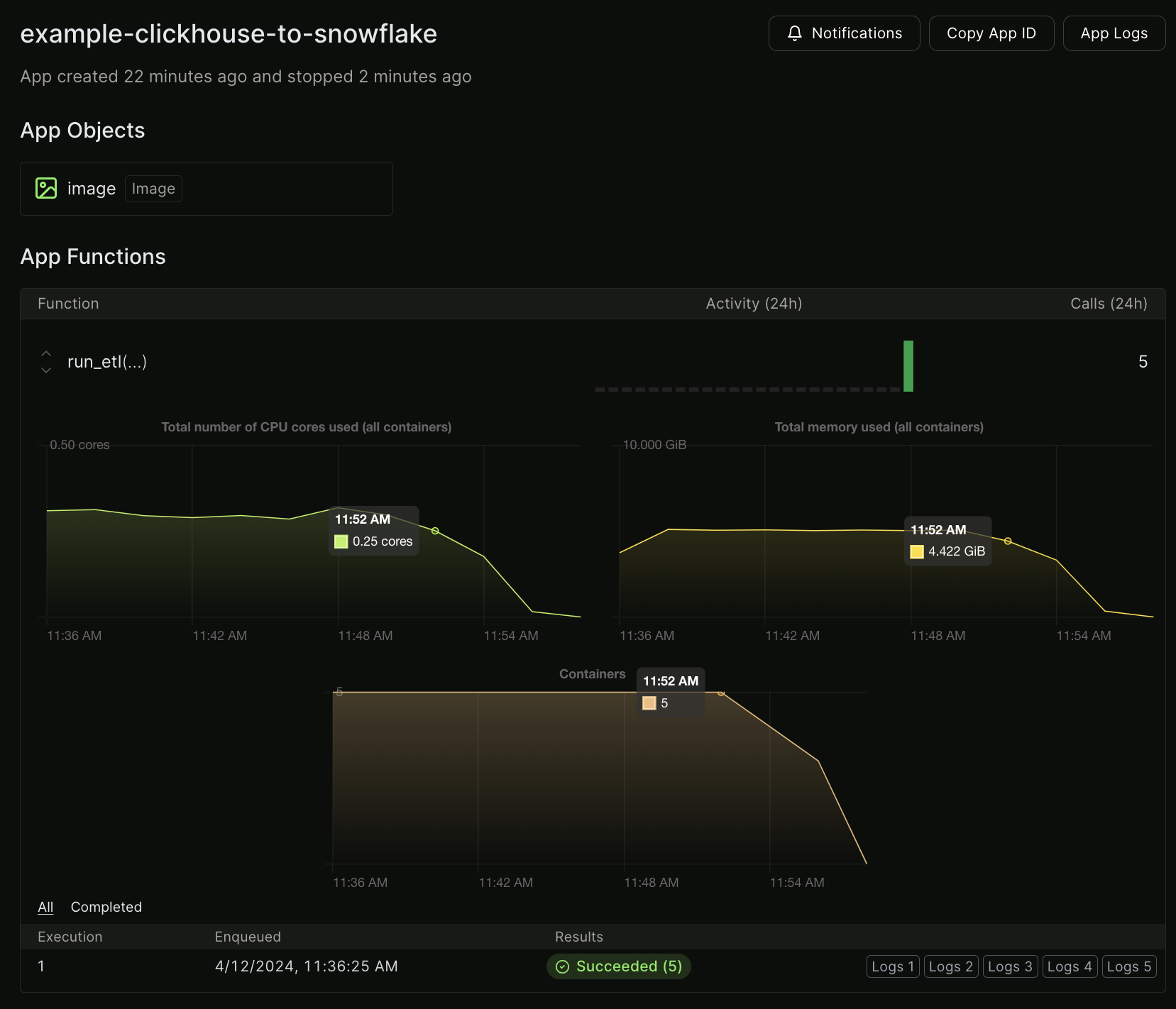
This job copied 12m rows from Clickhouse to Snowflake in 16 minutes using:
- 5 CPUs: at $0.192 / CPU hour that comes out to $0.26
- 4.4 GiB of memory: at $0.024 / GiB per hour that comes out to $0.03
Even if Fivetran had a ClickHouse connector (it doesn’t at the time of this writing), syncing 12m rows would cost ~$3300. The total cost of this Modal job is $0.29 (0.01% of Fivetran).
You could argue that the Modal job costs more in developer time compared to an ETL vendor. In my opinion (and hopefully yours too after reading the code snippets!), this example was quite simple; I’d estimate an analytics engineer could write this in less than a day and spend at most a few hours a month maintaining it.
And this is where the real cost savings come in: by making your engineers more productive. In this next example, we’ll show how easy it is to write your own custom data jobs on Modal.
Example 2: Enrich user data with the Github API
Most of our customers first sign up using their username. However, we also want to know what company they work for so we can see if they would be interested in our Team or Enterprise tier. One way to get that information is from a user’s Github profile:
First, we extract some user ids and associated Github usernames from our data warehouse:
def get_usernames():
import snowflake.connector
conn = snowflake.connector.connect(
user="snowflake_user",
password=os.environ["SNOWFLAKE_PASSWORD"],
account=os.environ["SNOWFLAKE_ACCOUNT"],
)
cursor = conn.cursor()
q = """
select
id,
github_username
from user
where github_username is not null
"""
cursor.execute(q)
df = cursor.fetch_pandas_all()
print(f"Got {df.shape[0]} rows.")
cursor.close()
conn.close()
return dfThen, we write a function to query the Github API for a user’s company:
def get_company(user):
from github import Auth, Github, GithubException
auth = Auth.Token(os.environ['PAT'])
g = Github(auth=auth)
try:
user = g.get_user(user)
except GithubException:
print(f"Request for {user} failed, skipping.")
return None
return user.companyFinally, we apply that function on our user data to get an enriched dataset with a user’s Github-listed company. To query the Github API, first create a personal access token and add it to Modal as a Secret:
def get_user_companies(df):
print("Querying Github API...")
df['company'] = df['GITHUB_USERNAME'].apply(get_company)
return df
@stub.function(
secrets=[
modal.Secret.from_name("kenny-github-secret"),
modal.Secret.from_name("snowflake-secret")
],
)
def main():
users_df = get_usernames()
enriched_df = get_user_companies(users_df)
print(enriched_df.head())Running this script gives us:
Got 100 rows.
Querying Github API...
Request for xxxx failed, skipping.
ID GITHUB_USERNAME company
0 us-abc xxxxxxxx Duke University
1 us-def xxxxxxxxxx None
2 us-ghi xxxxxxx None
3 us-jkl xxxxxxxxxxxx None
4 us-mno xxxxxxxxx NoneLooks like we need to schedule some college tours, starting with Duke 🔵😈
Let’s say you want to schedule this to run every day. This is as simple as
attaching a Period or
Cron argument into
@stub.function:
@stub.function(
secrets=[
modal.Secret.from_name("kenny-github-secret"),
modal.Secret.from_name("snowflake-secret")
],
# run this cloud function every day at 6am UTC
schedule=modal.Cron("0 6 * * *")
)The ETL vendors want you to be afraid of writing custom code, but hopefully this example shows you how easy it is to add your own custom logic to make simple, yet powerful data enrichments.
Conclusion (when to not use Modal for ETL)
Traditional ETL solutions are still quite powerful when it comes to:
- Common connectors with small-medium data volumes: we still have a lot of respect for companies like Fivetran, who have really nailed the user experience for the most common ETL use cases, like syncing Zendesk tickets or a production Postgres read replica into Snowflake. The only criticism we have is the pricing model, especially for larger data volumes.
- Long-running, business-critical, multi-stage pipelines: this is where you will get the value from an orchestration platform like Airflow e.g. function caching, partial retries, granular observability metrics. For what it’s worth, Modal is also actively thinking about how to address some of these use cases better.
The data community is going through a sea change, where people are realizing that writing custom code is actually an asset and not a cost. It reduces your risk of vendor lock-in, expands your universe of data solutions, and is orders of magnitude cheaper. Powered by Modal, your ETL process can finally unlock the flexibility, speed, and cost savings necessary in the new modern data era.
More examples
Check out these other Modal examples for common data and analytics use cases:
- Deploying a dbt project that transforms S3 data using the duckdb adapter
- Hosting Streamlit apps
- Sending daily reports to Google Sheets